
¿Cómo conectar Python con SQL Server?
Tengo un montón de datos. Y, ¿ahora? ¿Qué hago con ellos? ¿Cómo actúo frente a ellos? ¿ Cómo aprendo de los datos y genero conocimiento e inteligencia? Puede que esa sea una de las preguntas que te hagas en tu día a día como planificador de proyectos llevando el control de tus proyectos. Primavera P6 es una fuente de datos casi inagotable de la cuál puedes llegar a sacar provecho. Te vamos a enseñar cómo conectar Python con SQL Server para que saques el mayor rendimiento posible tanto de los datos estructurados como de los datos no estructurados dentro de Primavera P6 Professional. Are you ready?
SUSCRÍBETE A NUESTRO CANAL DE YOUTUBE
Paso inical para conectar Python con SQL Server
Antes de empezar con esta guía para conectar Python con SQL Server, deberás tener Primavera P6 previamente configurado en una base de datos SQL Server. Si aún no lo has hecho, echa un vistazo primero a nuestro artículo sobre cómo configurar una base de datos Microsoft SQL Server para Primavera P6 Professional. Del mismo modo, deberás tener instalado Python en tu computadora. Y si ya tienes todo listo, comencemos.
Configurar un nuevo «Login» en Microsoft SQL Server Management Studio
Accede a Microsoft SQL Server Management Studio
El siguente paso para conectar Python con SQL Server será abrir el gestor de base de datos Microsoft SQL Server Management Studio desde el menú «Inicio» de tu ordenador. En la ventana que se abre, con nombre «Connect to Server», elige el nombre del servidor donde se encuentre la base de datos de Primavera P6 con la que trabajas y presiona el botón «Connect».
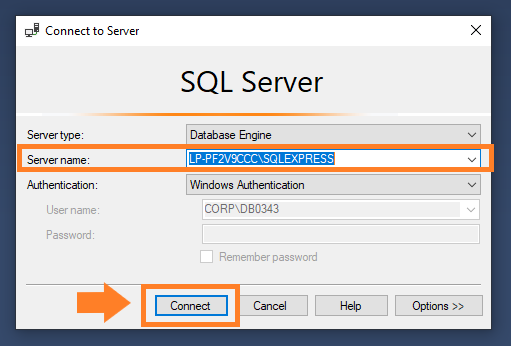
Es hora de crear un nuevo «Login» para realizar la conexión desde Python
Crea un nuevo Login ahora. Para ello, deberás acceder dentro de la carpeta «Logins», que se encuentra dentro de la carpeta «Security». Una vez dentro, con el botón derecho del ratón sobre la carpeta «Logins», haz clic en la opción «New Login».
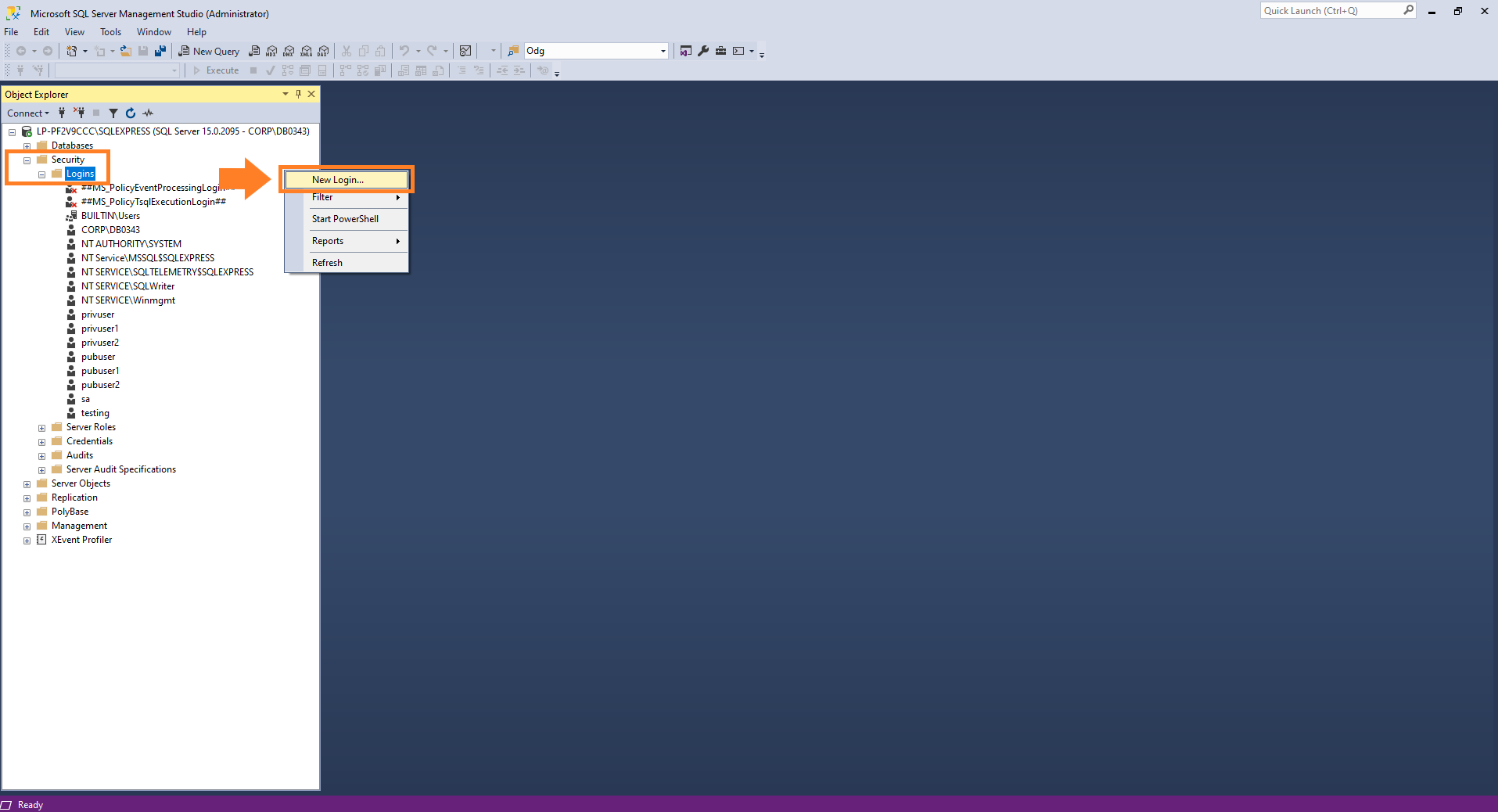
Configura tu nuevo «Login»
Se abrirá una nueva ventana que se llama «Login-New», donde podrás ver en la esquina superior izquierda una serie de páginas para poder navegar. En primer lugar, ve a la página que se denomina «General». En ella, deberás poner un nombre para loguear. En nuestro caso hemos seleccionado «project2080». Selecciona la opción «SQL Server authentication» y añade una contraseña. Nosotros hemos elegido «Project*2080» como contraseña. Recuerda apuntarlo porque necesitarás estos dos datos a la hora de realizar la conexión desde Python. En el campo correspondiente a «Default database» selecciona la base de datos que usas para Primavera P6 Professional. En nuestro caso es «PROJECT2080».
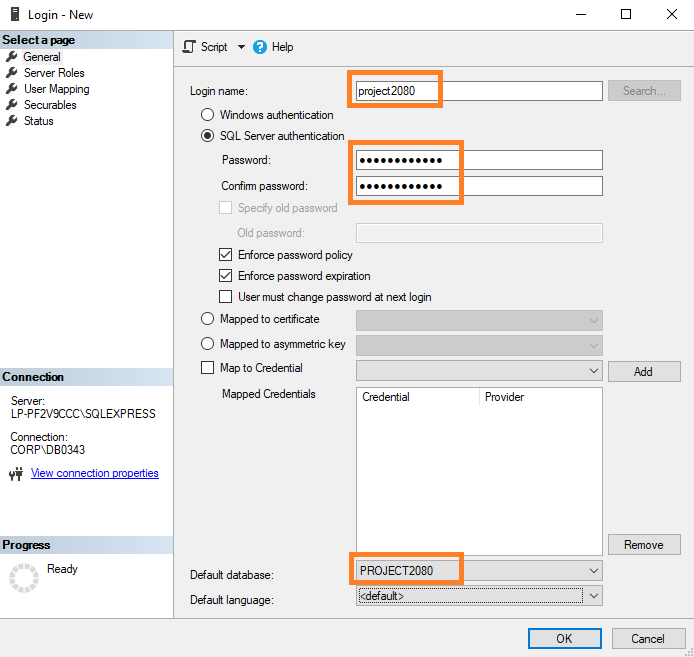
En la página «Server Roles», asegúrate de marcar la función «sysadmin». La opción «public» viene por defecto y la puedes dejar marcada también si tu perfil es público.
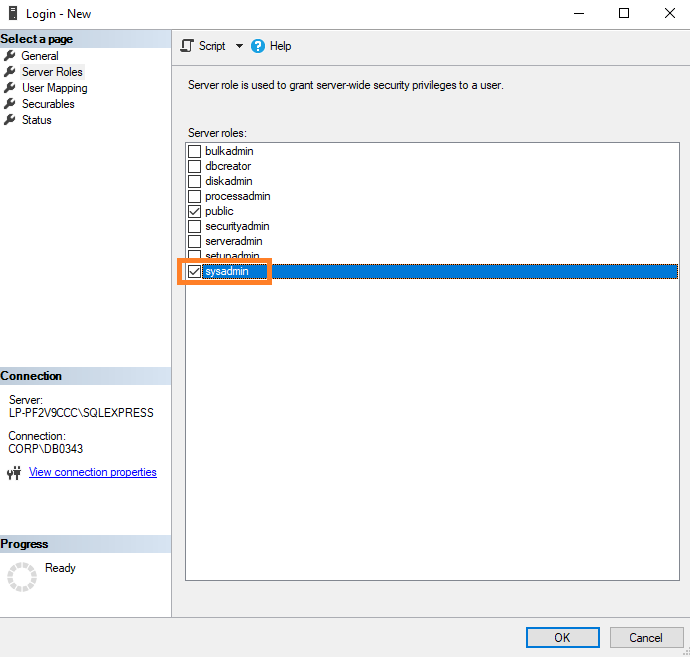
Asegúrate de que en cada una de las ventanas siguienes tienes haces la misma selección que te mostramos a continuación.
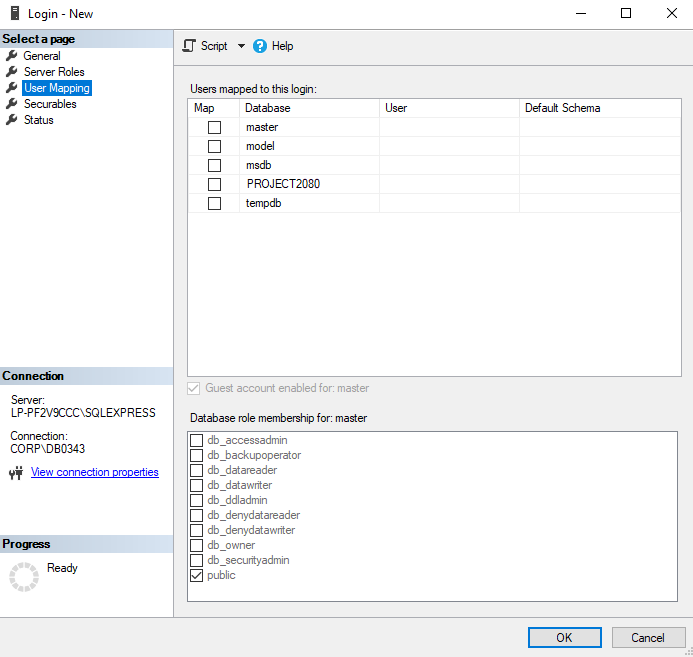
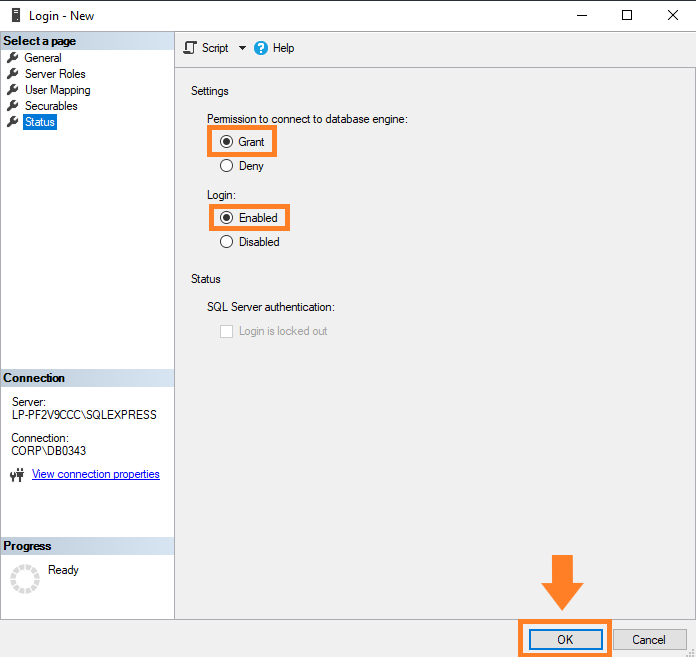
Por último, en la página «Status», asegúrate de tener marcadas las opciones que te mostramos en el siguiente pantallazo. Presiona «Ok» para continuar.
Una vez se haya cerrado la ventana, cierra la conexión y vuélvela a abrir. Ya habrás terminado con la configuración de acceso y podrás comenzar con la conexión con SQL Server desde Python.
Cómo crear una conexión con SQL Server desde Python
Una vez hayas creado el nuevo «Login», es hora de conectar Python con SQL Server. Para ello, abre un nuevo notebook en Python y crear una conexión con SQL Server. De este modo, podremos tener acceso total a las tablas, campos y registros de la base de datos de Primavera P6.
Configuración del entorno en Python
En este primer paso, vamos a importar las librerías que nos van a hacer falta para realizar la conexión de Python con SQL Server. Para este artículo, sólo necesitaremos las librerías «pyodbc» y «pandas», como se muestra en el siguiente código.

Crear conexión con SQL Server
Para poder trabajar, vamos a leer los datos de la base de datos de Primavera P6 (en nuestro caso, se llama «PROJECT2080») que se encuentra en `SQL Server`. Para ello, vamos a crear una conexión a SQL Server gracias al usuario `project2080` que previamente hemos creado. También necesitarás descargar e instalar el controlador ODBC para SQL Server, para poder realizar la conexión con la librería «pyodbc» de Python.
Usa el siguiente código en Python y asegúrate de poner las cuatro variables según lo hayas configurado tú en tu ordenador.

Crear dataframes basados en consultas a la base de datos
A continuación, vamos a crear dos dataframe:
- el primer dataframe mostrará las tablas que hay en nuestra base de datos de P6
- el segundo dataframe hará referencia a los campos o columnas de la base de datos.
Para ello, será necesario crear un cursor a la conexión para poder ir almacenando la información en memoria. Mediante consultas o «queries» accederemos a las tablas de nuestra base de datos de Primavera P6 Professional. Por último, guardaremos estas consultas como dataframes que inspeccionaremos a continuación. A continuación, puedes echar un vistazo al código a usar en Python.

Asegúrate de cerrar el cursor.
Tras conectar Python con SQL Server: inspecciona los datos
Ya tenemos guardados dos dataframe: uno que hace referencia a las tablas de nuestra base de datos y otro que hace referencia a las columnas. En este último paso, vamos a inspeccionar ambos dataframes para ver qué tipo de datos hemos obtenido. Para hacer una inspeccción básica, lo haremos mediante las funciones .info() y .sample().
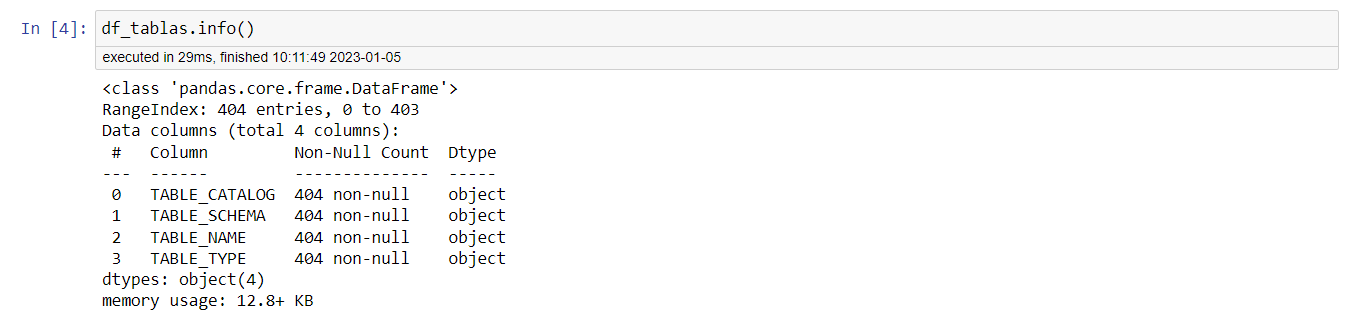
Como has podido observar, ya tenemos mucha información sobre el dataframe de las tablas (df_tablas) usando la función .info(). Hay 404 entradas que van de la 0 a la 403. El número total de columnas es 4, las cuales vienen identificadas con un número de índice (#), el nombre de la columna («Column»), el número de valores no nulos («Non-Null Count») y el tipo de dato («Dtype). Nuestras tablas no presentan ningún valor no nulo, y los datos son del tipo «object». Por último, podemos ver que se ha usado 12.8 kB de memoria.
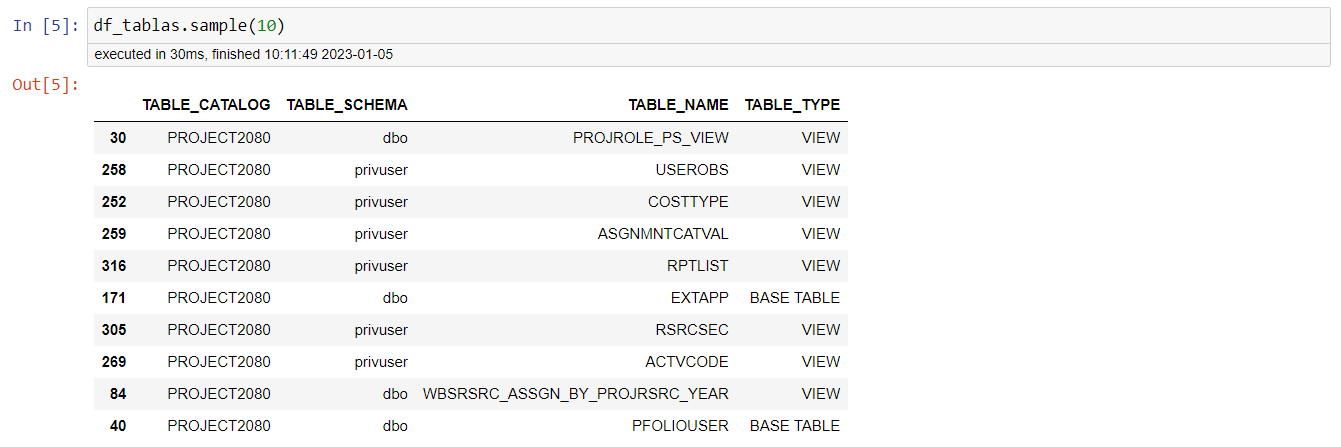
Cuando usamos la función .sample() vemos una muestra aleatoría de 10 filas de nuestro dataframe de las tablas (df_tablas). Al poner el número 10 dentro del paréntesis, le estamos diciendo a Python que nos devuelva únicamente 10 filas del dataframe.
Si quieres saber cómo inspeccionar el dataframe con las columnas de nuestra base de datos de Primavera p6, puedes descargar el notebook completo sobre cómo conectar Python con SQL Server. En él también incluimos algunos filtros básicos para ver cuáles son las columnas «Primary Key» de cada tabla de la base de datos de P6.
EN PROJECT 2080 NOS GUSTARÍA QUE RECORDARAS
Te dijimos que íbamos a comenzar a aplicar el Data Science y el Deep Learning a la Planificación y Control de Proyectos, y lo hemos cumplido. Conectar Python con SQL Server es sólo el primer paso. Quizá no te conviertas en un experto en programación con Python o un gurú en SQL, pero sí que tendrás todas las herramientas necesarias para poder hacer un análisis exhaustivo de tus cronogramas de actividades, encontrar patrones y hacer un análisis predictivo de tus proyectos. Y nosotros te vamos a enseñar a hacerlo. Así que si no lo has hecho aún:
SUSCRÍBETE A NUESTRO CANAL DE YOUTUBE


18 diciembre, 2023 @ 15:36
Thank you for this interesting information.
Do you have more, on how we can access a project, activities, manipulate data from the project?
24 enero, 2024 @ 07:25
Hi Alex,
We are working on a new post to show you how to do a data science project using Primavera P6 data and Python. Not sure when it will be released.
Regards,